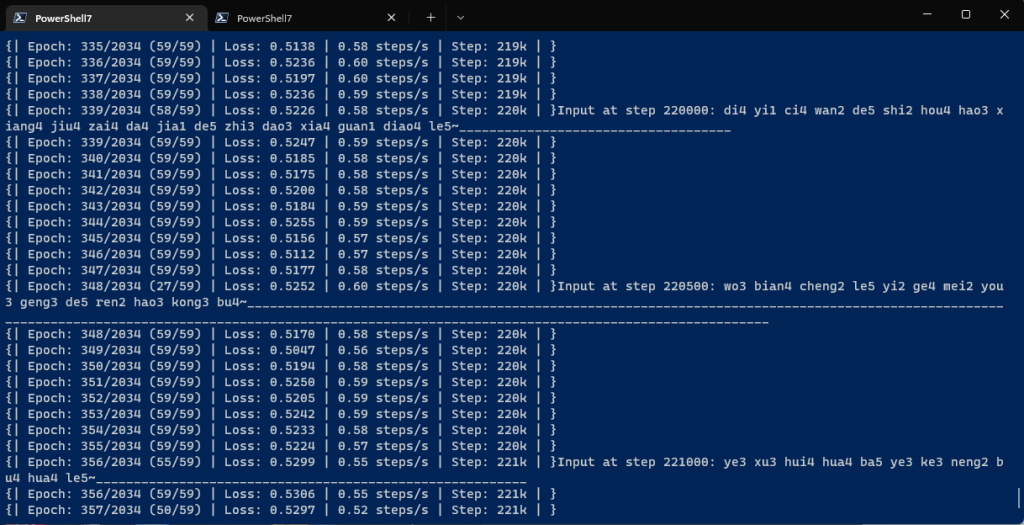
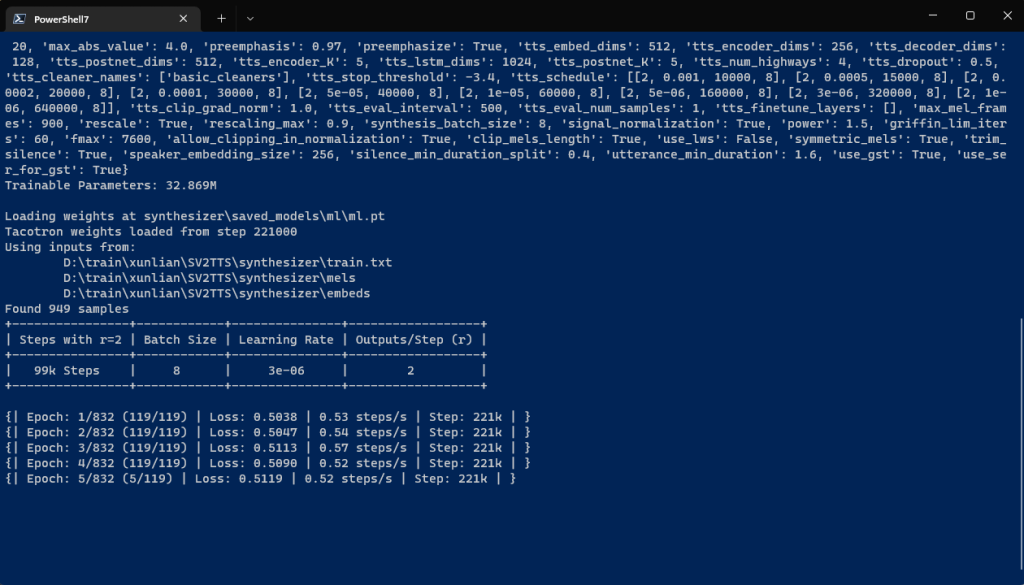
昨天晚上从网上下载了一个200k步的模型(阿梓的那个)接着跑,早上起来看了看,现在是221k步
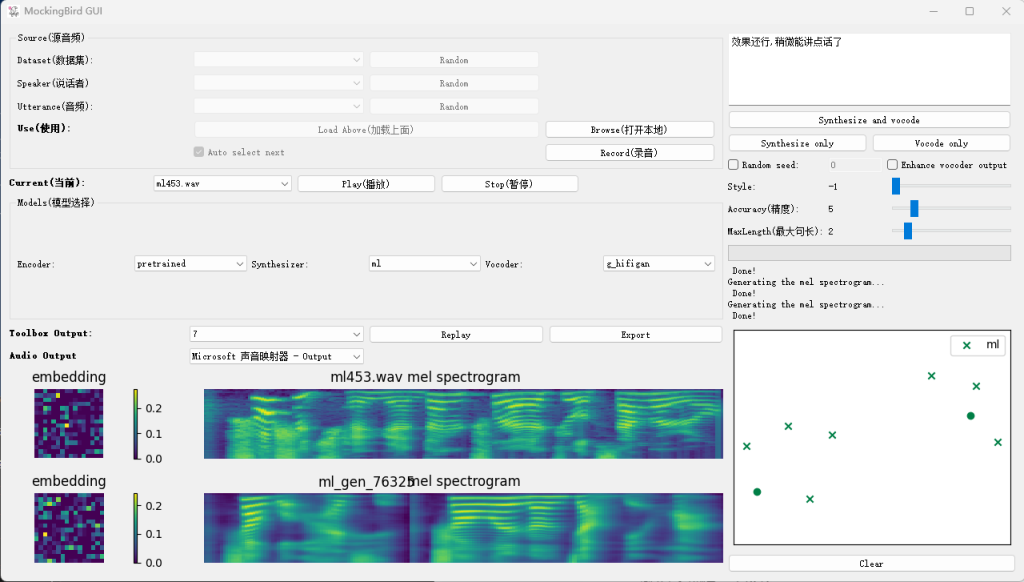
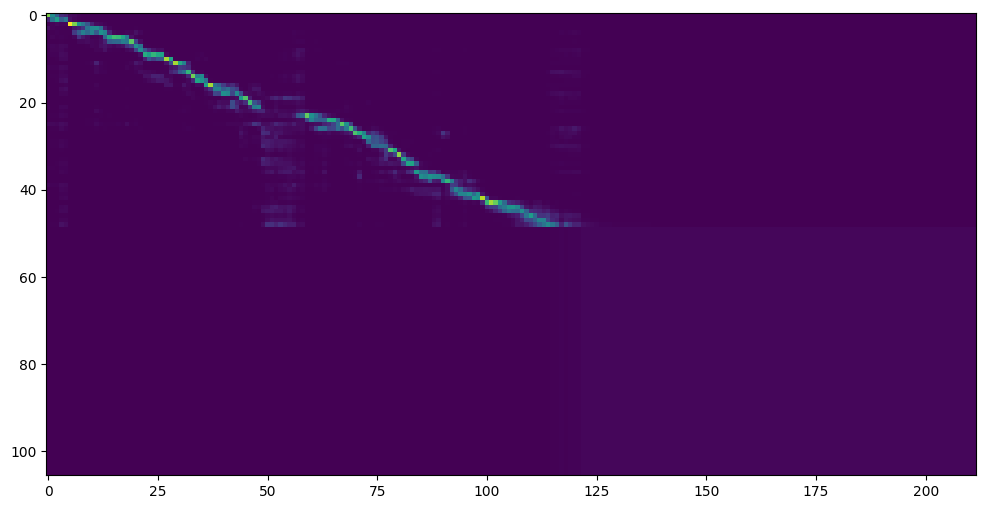
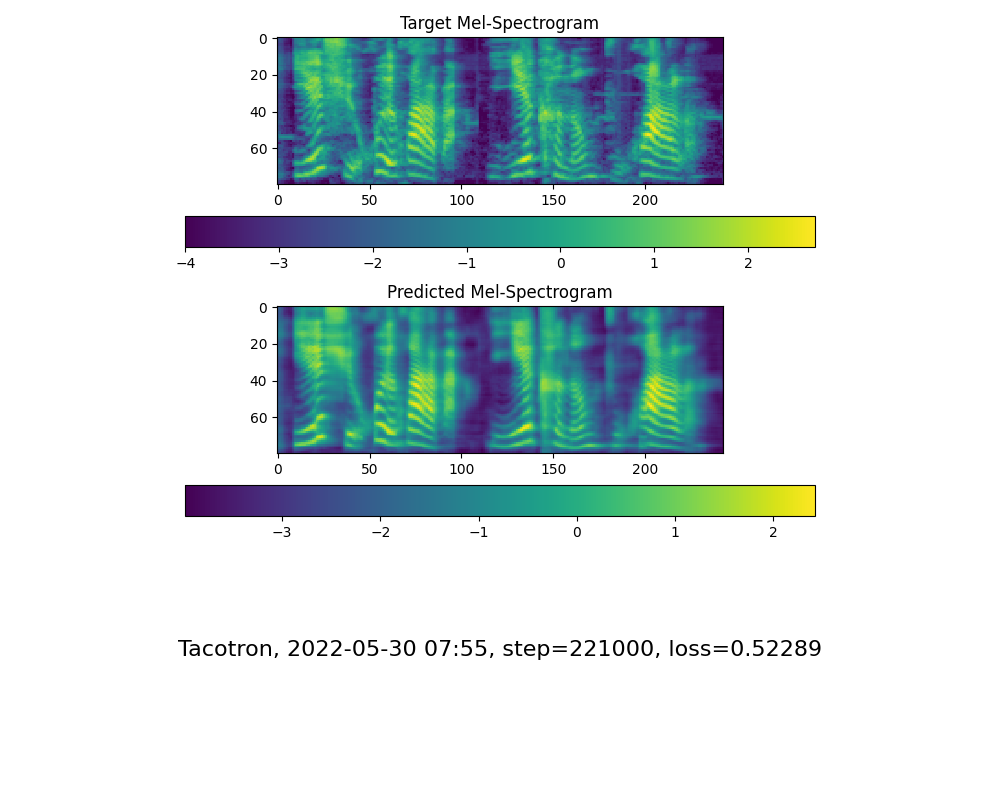
嗯,现在声音已经挺像的了,稍微有点电音,说话的风格稍微保留了一点点原来模型的风格
输入语音(current):
生成的语音有点那味了
对了,挂一个茉里mari的b站账号:https://space.bilibili.com/690608686
但是loss感觉降低不下去了,是不是数据准备的有点少,是不是过拟合了?到时候得再准备点数据去了
跑的是准备的914条语音,不过其实质量有点低,那天录播主播感觉有点口齿不清,准备稍微删掉点太短的和听不清的,然后再从网上下载一点再标…
读书回挺不错的,口齿清晰,最关键是不磕磕巴巴,但是感觉说出来的话可能和平时不太一样
哎,之前我下的那个录播就是,经常出现这种句子(举例):然后…然后…就…但是如果每天都杂谈唱歌的话
话说笔记本已经连着跑了两天了,停下来休息休息吧

今天又去搞了点声音样本,接着跑!从914个到现在1559个了!
而且这次我选语音的质量比上次要高一点,冲冲冲,继续跑!
0 条评论