在执行python synthesizer_train.py ml E:\xunlian\SV2TTS\synthesizer 的时候报错
查看报错可以看到
TypeError: Descriptors cannot not be created directly.
If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.
If you cannot immediately regenerate your protos, some other possible workarounds are:
- Downgrade the protobuf package to 3.20.x or lower.
- Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).
解决方法 : pip install protobuf==3.20.0 (protobuf版本太高了,降级)
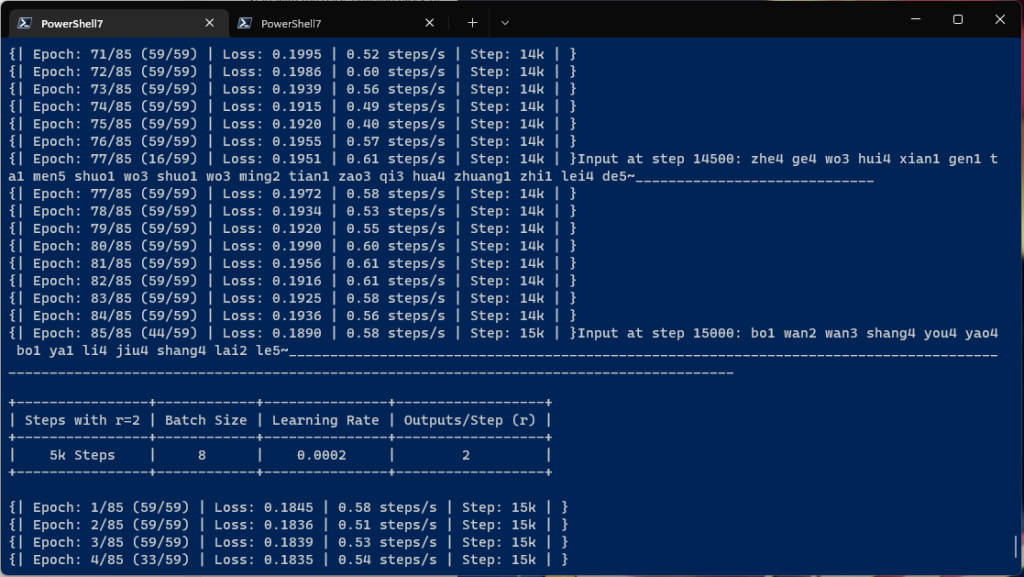
训练中…不知道是显卡太差还是训练数据放在机械盘的缘故,好慢啊…(看教程说要500G以上的空间,等我训练完了看看单个要多少空间)(现在跑到了10K步,好像并没有变大太多)
?????我看了看大小,怎么是我的MockingBird程序路径在变大啊!我D盘固态只剩30个G了啊!
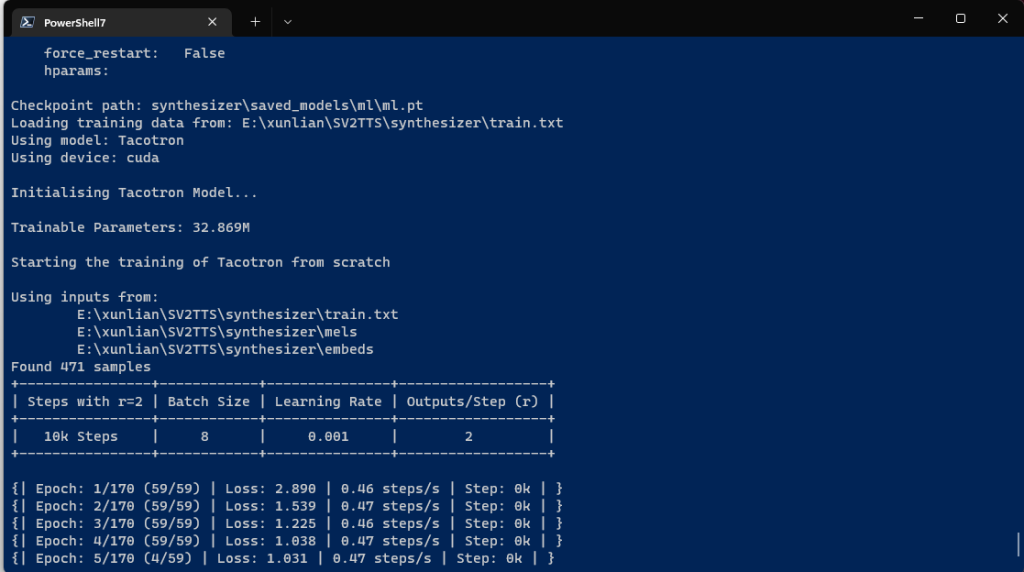
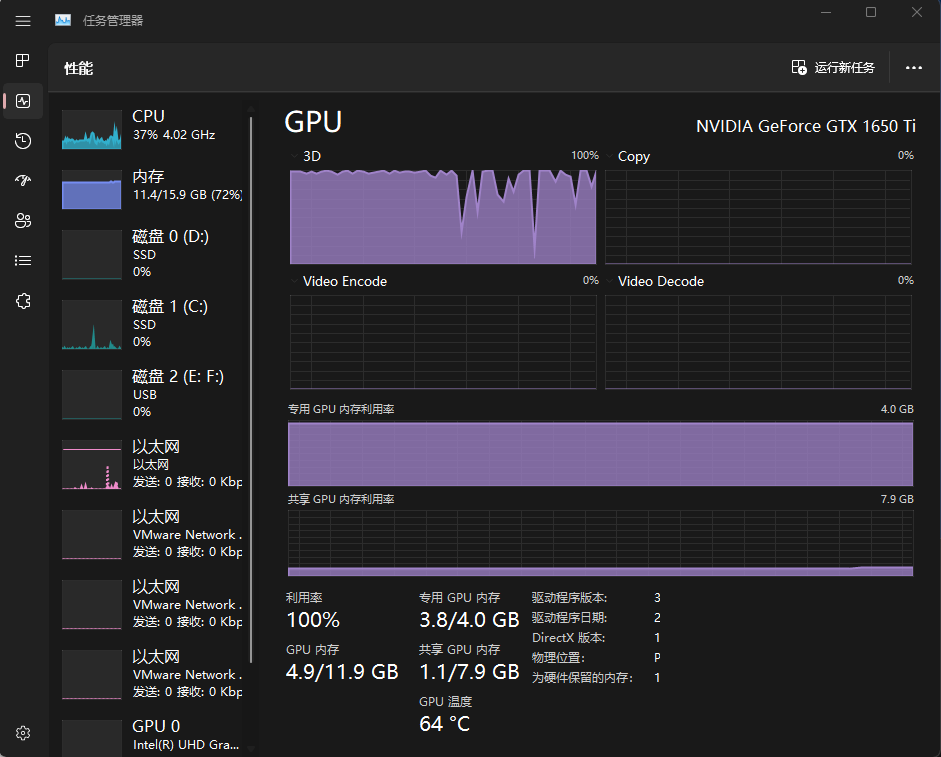
现在是下午3:10分,跑到第9000步了,感觉寄了,

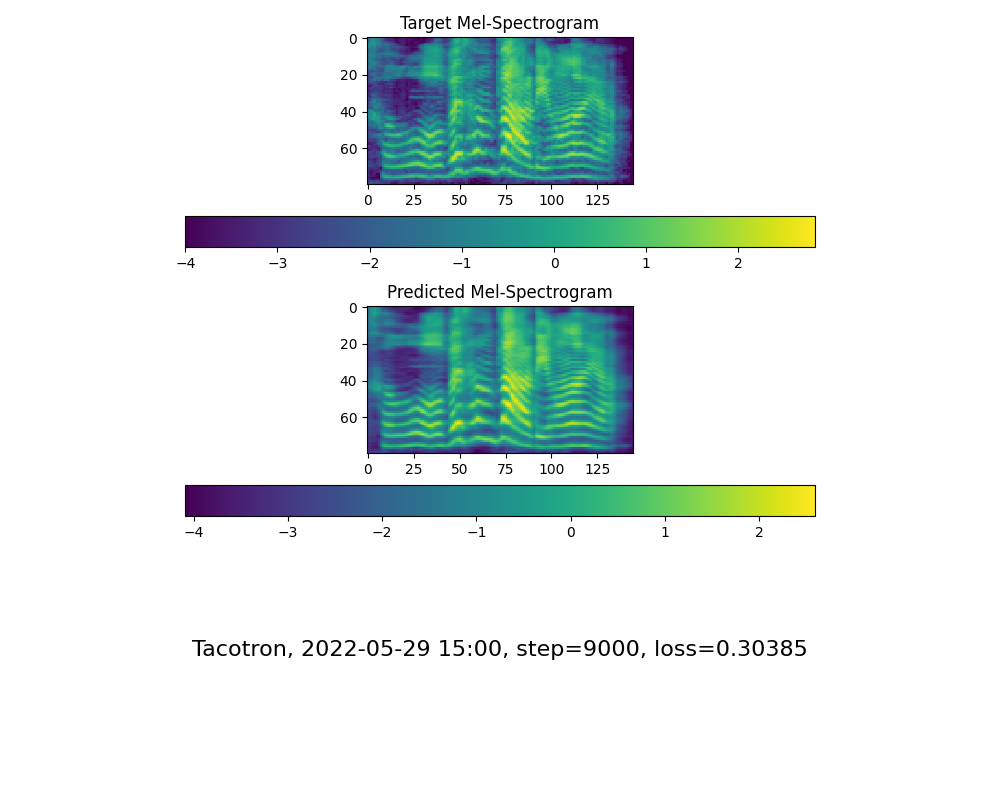
准备了1000个样本还是不够吗
7.什么时候算训练完成?
首先一定要出现注意力模型,其次是loss足够低,取决于硬件设备和数据集。拿本人的供参考,我的注意力是在 18k 步之后出现的,并且在 50k 步之后损失变得低于 0.4
再看了下,官方的跑了18k步,那我准备的还是不够啊…
还有就是我准备声音样本的质量不太够吧
不管,等跑完看看效果!

不是,正等着看效果呢,怎么还有啊…
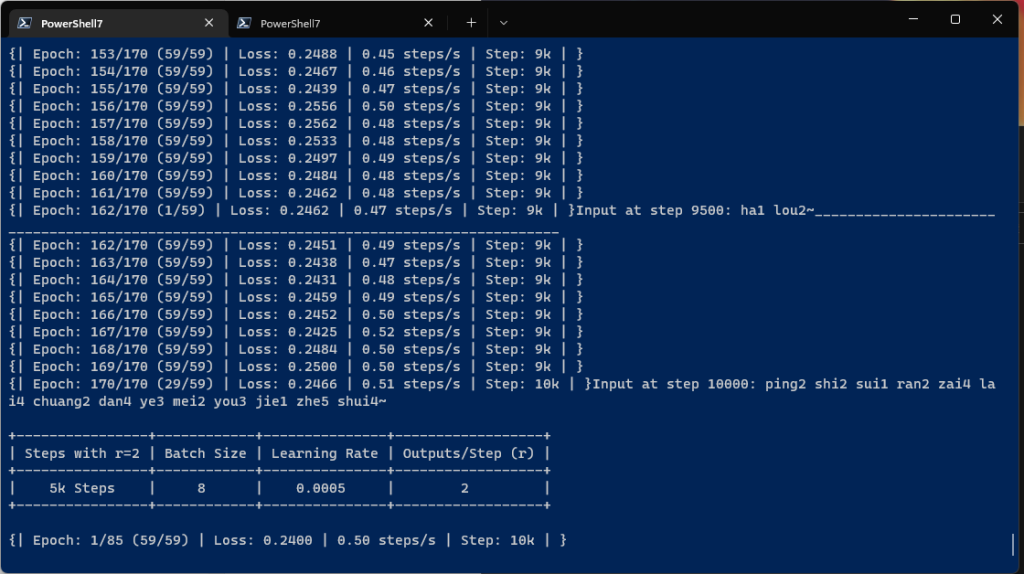
一些别人的经验:
1,尽量只有一个人声
2,背景音乐尽量少
3,人声的语调尽量平和
4,人声尽量不要有口头语,并且说话内容大多是长句
5,如果有多个发音人,要分别放在train目录下的不同子文件夹内
6,尽量不要有汉字以外的字符,数字和英文尽量替换成同样读音的中文字符
7,可以用拼音代替文字,制作数据集和运行软件时都可以使用这种方法 例如:
数据集→shu4 ju4 ji2
七海→qi1 hai3
轻音对应的数字为5
8,如初背景音乐的软件效果也比较有限,如果可以的话还是有先用纯语音 作者:什么都懂一点的奶糖 https://www.bilibili.com/read/cv13991144?spm_id_from=333.999.0.0 出处:bilibili
我又看了看别人的教程,突然发现尽然还可以把别人训练过的模型拿过来接着训练…啊这…那我今天这不是白训练了…(后来下了三个别人的,发现只有一个能接着训练,有可能是软件版本的关系)
来了,第三轮来了,关于在已经训练好的模型继续训练的问题…我觉得我还是先跑着,到明天再说吧
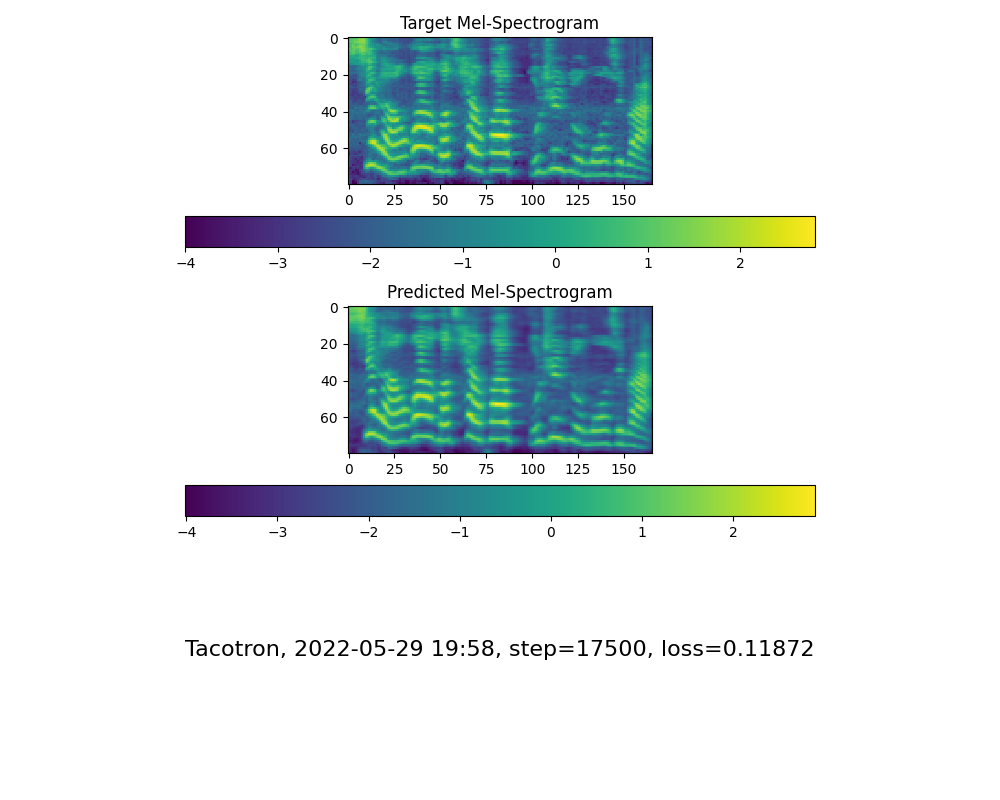
今日总结:明天再搞搞
今天晚上就接着一个200k步的模型接着跑,看看明天早上起来效果怎么样

0 条评论